标注
保研
测试用例
模型蒸馏
社区论坛
AOE网
雨滴传感器
数字图像处理
图像分割
BH1750
符号同步
工业互联网
MVCC
舌苔
学生HTML网页作业作品
C/C++面试
SIFT
非线性函数拟合
轮廓
信息可视化
Spark sql
2024/4/24 2:19:18
Spark SQL精华 及与Hive的集成
文章目录一.SQL on Hadoop二.Spark SQL1.Spark SQL前身2.Spark SQL架构3.Spark SQL运行原理三.Spark SQL API1.Dataset (Spark 1.6)2.DataFrame (Spark 1.4)四.Spark SQL支持的外部数据源1.Parquet文件:是一种流行的列…

spark sql cbo与rbo考量
目录 概述RBOCBO结束 概述
Spark SQL 的优化器有两种优化形式:一种是基于规定的优化形式 (Rule-Based Optimizer,简称为RBO);另一种是基于代价的优化形式(Cost-Based Optimizer,简称为CBO)。
RBO
RBO 依照已有的规则࿰…
Spark性能优化实战总结
1、成本考虑
重要且紧急的,优先级高重要不紧急,等人力空闲再优化
2、优化方向
2.1、参数优化(优先)
2.1.1 读取相关
// 使用scan hive方式读取hive表时,调小maxsize,可增大读取的task任务数
spark.had…
大数据常见面试题之spark sql
文章目录一.创建DataSet的几种方式二.DataFrame相对RDD有哪些不同三.SparkSql如何处理结构化数据和非结构化数据四.RDD DataFrame DataSet的区别1.RDD2.DataFrame3.DataSet五.spark sql运行流程六.spark sql原理七.spark sql 中缓存方式八.spark sql中join操作与left join操作区…

spark sql和jdbc将数据写入mysql的对比
目录jdbcspark sql引用的库类效率对比连接mysql错误jdbc
public static void jdbc() {// test为数据库名,spark为表名final String url "jdbc:mysql://localhost:3306/test";final String username "root";final String password "123…
Dataset 的一些 Java api 操作
文章目录 一、使用 Java API 和 JavaRDD<Row> 在 Spark SQL 中向数据帧添加新列二、foreachPartition 遍历 Dataset三、Dataset 自定义 Partitioner四、Dataset 重分区并且获取分区数 一、使用 Java API 和 JavaRDD 在 Spark SQL 中向数据帧添加新列 在应用 mapPartition…

Spark编程实验三:Spark SQL编程
目录
一、目的与要求
二、实验内容
三、实验步骤
1、Spark SQL基本操作
2、编程实现将RDD转换为DataFrame
3、编程实现利用DataFrame读写MySQL的数据
四、结果分析与实验体会 一、目的与要求
1、通过实验掌握Spark SQL的基本编程方法; 2、熟悉RDD到DataFram…

1.SparkSQL基础—Spark SQL概述、Spark SQL核心编程—DataFrame(重要)、DataSet 与 RDD 之间相互转换
本文目录如下:第1章 Spark SQL概述1.1 DataFrame(数据帧)简介1.2 DataSet(数据集)简介第2章 Spark SQL核心编程2.1 新的起点2.2 DataFrame(重要)2.2.1 创建 DataFrame (重要)2.2.1.1 从 Spark 数…
2.SparkSQL—核心编程—IDEA 开发 Spark SQL、用户自定义函数—UDF、UDAF—强类型、弱类型
本文目录如下:2.6 IDEA 开发 Spark SQL2.6.1 添加依赖2.6.2 代码实现2.7 用户自定义函数2.7.1 UDF2.7.2 UDAF (常用)本章节最重要的部分是第 2.7.2小节 中的第 (3) 点: UDAF (常用)。 2.6 IDEA 开发 Spark SQL
实际开发中,都是使用 IDEA 进行开发的。
…
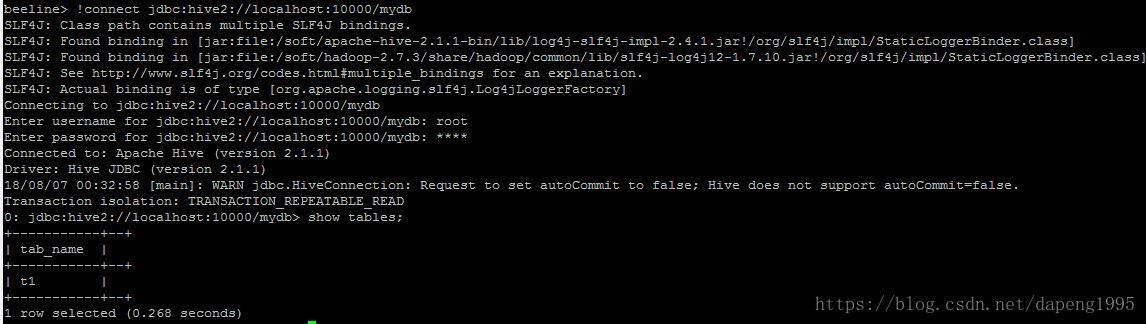
Spark基础:(六)Spark SQL
1、相关介绍
Datasets:一个 Dataset 是一个分布式的数据集合 Dataset 是在 Spark 1.6 中被添加的新接口, 它提供了 RDD 的优点(强类型化, 能够使用强大的 lambda 函数)与Spark SQL执行引擎的优点。
DataFrame: 一个 DataFrame 是…
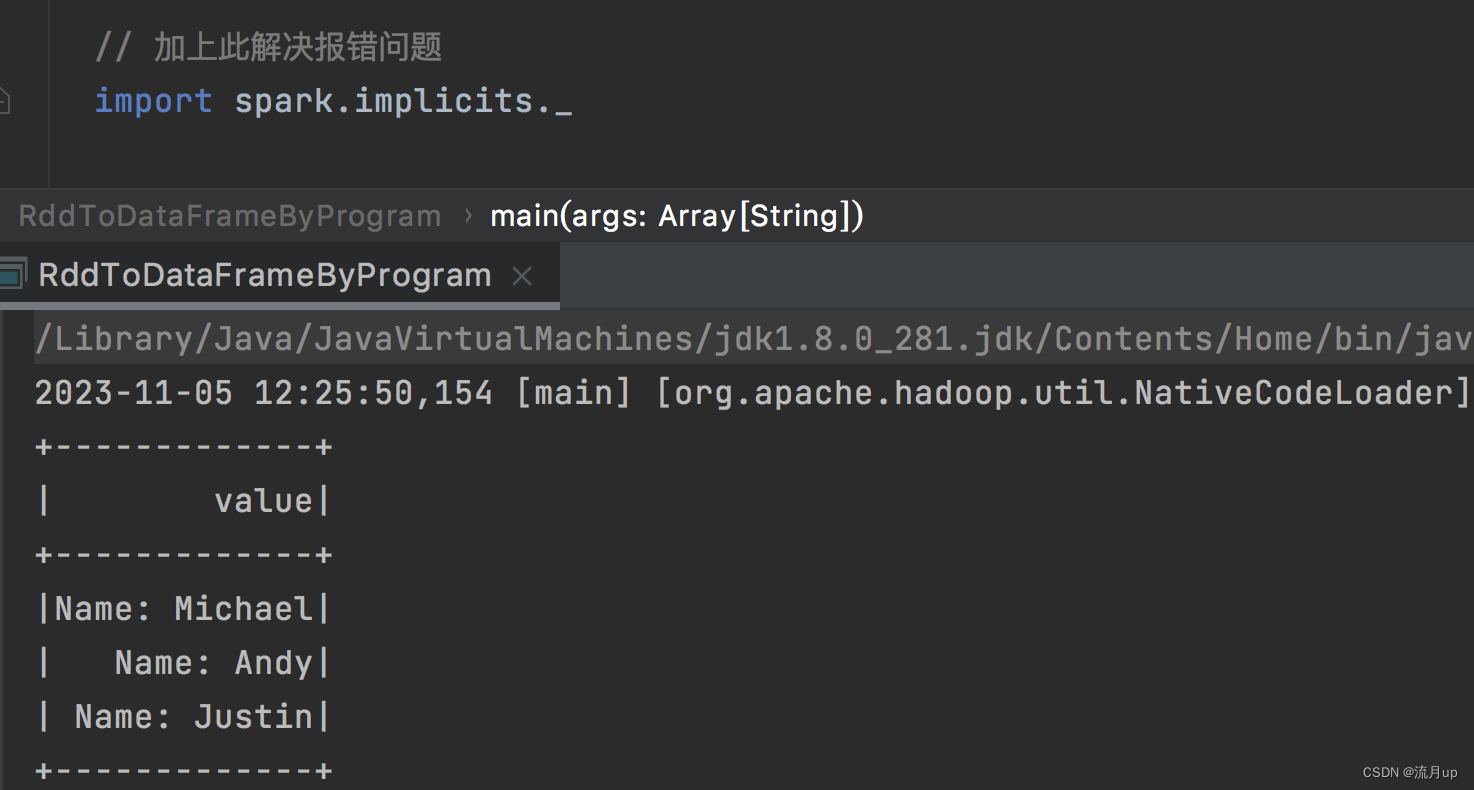
7.spark sql编程
概述 spark 版本为 3.2.4,注意 RDD 转 DataFrame 的代码出现的问题及解决方案 本文目标如下:
RDD ,Datasets,DataFrames 之间的区别入门 SparkSession创建 DataFramesDataFrame 操作编程方式运行 sql 查询创建 DatasetsDataFrames 与 RDDs 互相转换 使用…
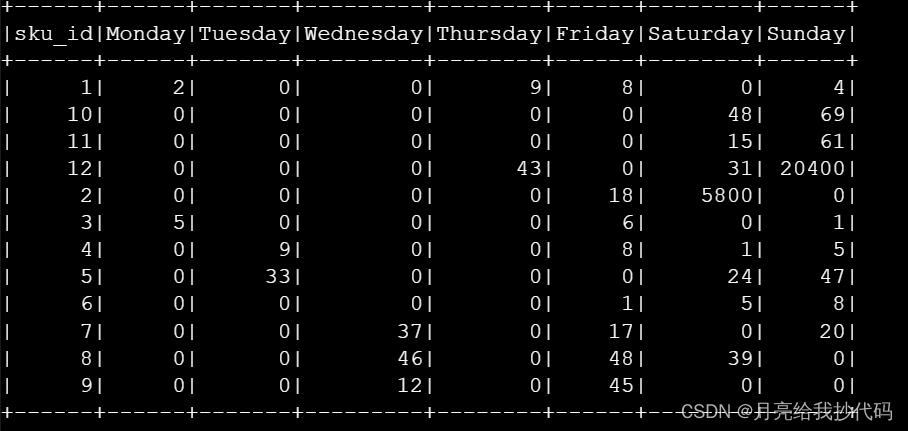
Hive Cli / HiveServer2 中使用 dayofweek 函数引发的BUG!
文章目录 前言dayofweek 函数官方说明BUG 重现Spark SQL 中的使用总结 前言
使用的集群环境为:
hive 3.1.2spark 3.0.2
dayofweek 函数官方说明
dayofweek(date) - Returns the day of the week for date/timestamp (1 Sunday, 2 Monday, …, 7 Saturday).
…

Spark Sql 转换成Task执行 和 InsertIntoHiveTable写入hive表数据 源码分析
1.3.1 InsertIntoHiveTable类源码解析
1.3.1.1 背景 读取数据,经过处理后,最终写入 hive表,这里研究下写入原理。抛出如下几个问题?
1、task处理完数据后,如何将数据放到表的location目录下?
2、这类写入…
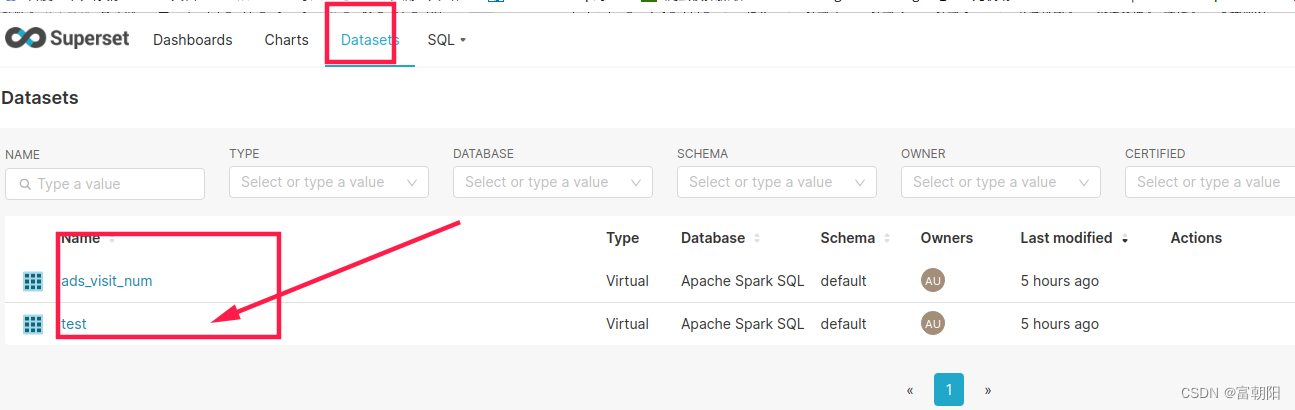
superset连接Apache Spark SQL(hive)过程中的各种报错解决
superset连接数据库官方文档:Installing Database Drivers | Superset
我们用的是Apache Spark SQL,所以首先需要安装下pyhive #命令既下载了pyhive也下载了它所依赖的其他安装包
pip install pyhive#多个命令也可下载
pip install sasl
pip install th…

spark sql 快速体验调试
spark sql提供了更快的查询性能,如何能够更快的体验,开发和调试spark sql呢?按照正规的步骤我们一般会集成hive,然后使用hive的元数据查询hive表进行操作,这样以来我们还需要考虑跟hive相关的东西,如果我们…