本专栏是杨伟超对Python软件的系列介绍
1 Python简介
根据官网宣传:Python[1]是一种面向对象的解释性高级编程语言,具有动态语义。
在不同的教材里面,有不同的关于python的定义。但共通的一点是:Python是一门简洁且功能强大的语言。比起C或者C++语言,它可以让你用相当简短的代码实现所需的功能。Python具有很多功能强大的包(比如numpy,pandas等),调用这些包可以实现许多功能。比如调用Tensorflow包可以实现复杂的神经网络算法,调用matplotlib包可以画出漂亮的图表;这些功能在C或者C++里面都是很难实现的。
统计上经常用R语言,在我个人看来,Python语言的简洁程度和R差不多,但Python里面包更全,功能更强大,并且计算速度也更快。笔者曾经利用R语言读取一份基因数据,花了半个小时还没有读取成功;但利用特定的Python包,只用几秒钟就成功读取了数据。
尽管很多统计从业者倾向于使用R语言,但我们也很有必要学习一下Python作为补充。对于一些R语言很难实现的功能,就可以考虑使用Python来完成。
2 安装Python
一种方法是在Python官网里面下载Python的安装程序,但对于初学者而言,我个人更倾向于直接安装Anaconda。
Anaconda[2]是一个可用于科学计算的Python发行版。这是什么意思呢?Python是一门编程语言,使用这门语言的时候,在写代码这件事情之外,还有很多其他的配套工作,比如运行脚本、下载各种需要用到的库、管理环境等。Anaconda就把这些功能全都集成好了,省去很多琐碎的工作。简单来说,Anaconda帮你管理了在使用Python时用到的包和环境。并且以后在安装包的时候,可以直接利用Anaconda来安装,相当省时省力。
关于如何安装Anaconda的教程很多,大家也可以参考一下这两个教程:https://mp.weixin.qq.com/和https://blog.csdn.net/ITLearnHall/article/details/81708148
3 选择IDE
集成开发环境[3](IDE,Integrated Development Environment)是用于提供程序开发环境的应用程序,一般包括代码编辑器、编译器、调试器和图形用户界面等工具。集成了代码编写功能、分析功能、编译功能、调试功能等一体化的开发软件服务套。所有具备这一特性的软件或者软件套(组)都可以叫集成开发环境。
Anaconda里面也提供了很多的IDE,我个人比较喜欢使用的是jupyter notebook。因为它不但界面颜值高,画面简洁,并且代码运行的结果可以很清晰地显示出来,非常利于Python的学习。所以我后面会使用jupyter notebook来运行代码。关于jupyter notebook的介绍,可以参考https://www.jianshu.com/p/91365f343585
在本文中,为了方便展示,我使用了IPython。IPython[4]是一种基于Python的交互式解释器,提供了强大的编辑和交互功能。安装好Anaconda之后,就可以直接在Anaconda Prompt使用IPython了。
首先,可以先在开始界面找到Anaconda Prompt的图标,然后点击进入。
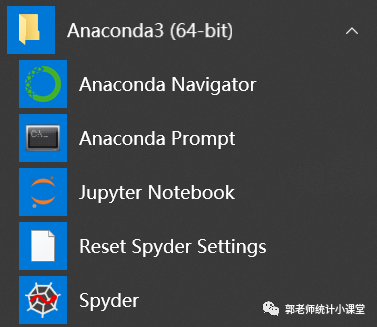
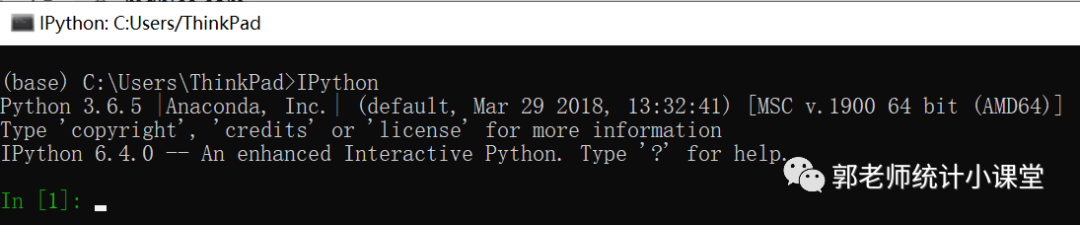
然后,在Anaconda Prompt界面里输入IPython ,就进入到IPython界面了
4 数据结构
数据结构是以某种方式(如通过编号)组合起来的数据元素(如数、字符乃至其他数据结构)集合。Python有自己独特的数据类型,使用不同的数据类型可以实现很多功能,这里我们介绍几种Python的数据结构。本次文章我们先介绍元组和列表,以及相关函数。
4.1 元组
元组是一个固定长度,不可改变的数据结构。这意味着我们不能修改里面的元素,下面说一些有关元组的操作。
- 生成
最简单的方法,就是用逗号分隔一列值
In [1]: tuple1 = 1,2,3In [2]: tuple1Out[2]: (1, 2, 3)还有一种方法,就是把值放在圆括号里面,如下所示:
In [3]: tuple2=(1,"a",2)In [4]: tuple2Out[4]: (1, 'a', 2)利用tuple函数也可以将其他的数据结构转换成元组
In [5]: tuple3 = tuple("string")In [6]: tuple3Out[6]: ('s', 't', 'r', 'i', 'n', 'g')- 索引
利用方括号,就可以访问元组中的元素,不过和R语言不同的是,序列是从0开始的。
In [10]: tuple3[1]Out[10]: 't'In [11]: tuple3[0]Out[11]: 's'- 串联
使用加号可以将元组连接起来
In [12]: tuple2+tuple3Out[12]: (1, 'a', 2, 's', 't', 'r', 'i', 'n', 'g')- 复制
元组乘上一个整数,就可以将元组复制整数遍,并且串联起来
In [13]: tuple1*3Out[13]: (1, 2, 3, 1, 2, 3, 1, 2, 3)- 拆分
也叫做解包。如果想要把元组里面的元素分给相同个数的变量的话,就可以利用代码所示的方法:
In [15]: a,b,c=tuple1In [16]: aOut[16]: 1In [17]: bOut[17]: 2但需要注意的是,左边变量的个数一定要等于元组里面元素的个数,否则会报错。
In [18]: a,b=tuple1---------------------------------------------------------------------------ValueError Traceback (most recent call last) in ()----> 1 a,b=tuple1ValueError: too many values to unpack (expected 2)- 计数
使用count函数,可以计算出元组中某个元素的频数
In [19]: tuple4 = 1,1,2,3,4In [20]: tuple4.count(1)Out[20]: 24.2 列表
与元组对⽐,列表的⻓度可变、内容可以被修改。
- 生成
可以使用方括号生成列表
In [21]: list1 = [1,2,3]In [22]: list1Out[22]: [1, 2, 3]可以使用list函数将其他的数据结构转化为列表:
In [23]: list2 = list(tuple2)In [24]: list2Out[24]: [1, 'a', 2]In [25]: type(list2)Out[25]: list- 添加或删除元素
可以使用append函数在列表末尾添加元素
In [33]: list1.append(4)In [34]: list1Out[34]: [1, 2, 3, 4]使用insert(a,b)函数将元素插入特定位置。其中a代表位置的索引(编号),b代表想要插入的元素:
In [39]: list1.insert(4,5)In [40]: list1Out[40]: [1, 2, 3, 4, 5]insert的逆运算是pop,它移除并返回特定位置的元素。pop里面的值代表要移除的元素对应的编号
In [41]: list1.pop(1)Out[41]: 2In [42]: list1Out[42]: [1, 3, 4, 5]remove函数被用来去除列表里面的某个特定元素。remove里面的取值代表要被去除的元素。需要注意的是,这个函数只能移除第一个特定元素。
In [43]: list3 = [1,2,1,2]In [44]: list3.remove(2)In [45]: list3Out[45]: [1, 1, 2]使用in和not in函数可以检测元素在不在列表里面。
对于in来说,返回值是TRUE,代表元素在列表里面,返回值是FALSE,代表元素不在列表里面。对于not in就反过来
In [46]: 1 in list3Out[46]: TrueIn [47]: 1 not in list3Out[47]: False- 串联
与元组类似,也可以使用加号把两个列表串联起来
In [51]: list1+list2Out[51]: [1, 3, 4, 5, 1, 'a', 2]使用extend函数,也可以实现列表的串联:
In [49]: list3.extend([3,4,5,6])In [50]: list3Out[50]: [1, 1, 2, 3, 4, 5, 6]- 排序
可以使用sort函数对列表里面的元素进行排序
In [52]: list4 = [2,3,1,8,10,9]In [53]: list4.sort()In [54]: list4Out[54]: [1, 2, 3, 8, 9, 10]sort有⼀些选项,有时会很好用。其中之⼀是二级排序key,可以以它为标准进行排序。例如,我们可以按长度对字符串进行排序:
In [56]: list5 = ['ab','a','abc']In [57]: list5.sort(key=len)In [58]: list5Out[58]: ['a', 'ab', 'abc']- 切片
这个操作类似于R语言中的切片,但还是有所不同。R语言中的切片可以取得编号对应的所有的元素,而Python不能取到最后一个数字所对应的元素。这里在示例里面说一下:
In [64]: list4[2:5]Out[64]: [3, 8, 9]list4的第2到5个元素分别为:3,8,9,10,而这里没有取到10,这说明切片操作里面并不会取最后一个编号所对应的数字。
切片也可以进行赋值:
In [66]: list4[2:5] = [100,99,98]In [67]: list4Out[67]: [1, 2, 100, 99, 98, 10]负数可以表示从后往前切片:
In [69]: list4[-5:-2]Out[69]: [2, 100, 99]另一种切片的方法,是利用list[a:b:c],其中a表示开始的编号,b表示结束的编号,c表示选择的步幅,如下所示:
In [70]: list4[-5:-2:1]Out[70]: [2, 100, 99]In [71]: list4[-5:-2:2]Out[71]: [2, 99]In [72]: list4[-5:-2:-1]Out[72]: []In [73]: list4[-2:-5:-1]Out[73]: [98, 99, 100]c如果是负数的话,可以表示从后往前进行取值。可以利用这样的方法将列表的元素颠倒过来。
- 序列函数
利用enumerate函数,可以得到列表中不同元素所对应的序号(索引):
In [79]: list(enumerate(list4))Out[79]: [(0, 1), (1, 2), (2, 100), (3, 99), (4, 98), (5, 10)]可以看到,生成了由六个元组构成的列表,其中每个元组的第一个元素表示序号,第二个元素表示在list4中对应的元素。
和sort函数类似,sorted函数可以对列表进行排序。
In [80]: list4Out[80]: [1, 2, 100, 99, 98, 10]In [81]: sorted(list4)Out[81]: [1, 2, 10, 98, 99, 100]zip函数可以把多个列表,元组或者其他序列组合成一个由元组构成的列表。zip函数在编程的时候有很广的应用,利用zip函数可以实现对于多个数据结构的循环
In [82]: list6 = [10,11,12]In [83]: list7 = ['b','o','y']In [84]: zip(list6,list7)Out[84]: In [85]: list(zip(list6,list7))Out[85]: [(10, 'b'), (11, 'o'), (12, 'y')]可以看到,zip函数并不能直接显示出结果,需要先利用list函数转化为列表。这是因为zip函数生成一种叫做“迭代器”的数据结构,我们后面再讲。包括前面的enumerate函数,也是生成的迭代器。
reversed函数可以从后往前迭代列表元素。这个函数是一个生成器(简单理解为创建迭代器的简单而强大的工具)。所以要把reversed函数的取值转化为列表,才可以显示出结果。
In [86]: list(reversed(list6))Out[86]: [12, 11, 10]如果觉得本文不错,请点赞关注!
参考资料
[1]Python: https://www.python.org/
[2]Anaconda: https://zhuanlan.zhihu.com/p/36398337
[3]集成开发环境: https://www.zhihu.com/question/289779838/answer/468517858
[4]IPython: https://www.zhihu.com/question/51467397/answer/1098115714