1、取自ResourceManager REST API’s指标;
https://hadoop.apache.org/docs/r2.8.4/hadoop-yarn/hadoop-yarn-site/ResourceManagerRest.html
http://<rm http address:port>/ws/v1/cluster/metricshttp://**.**.***.208:8088/ws/v1/cluster/metrics
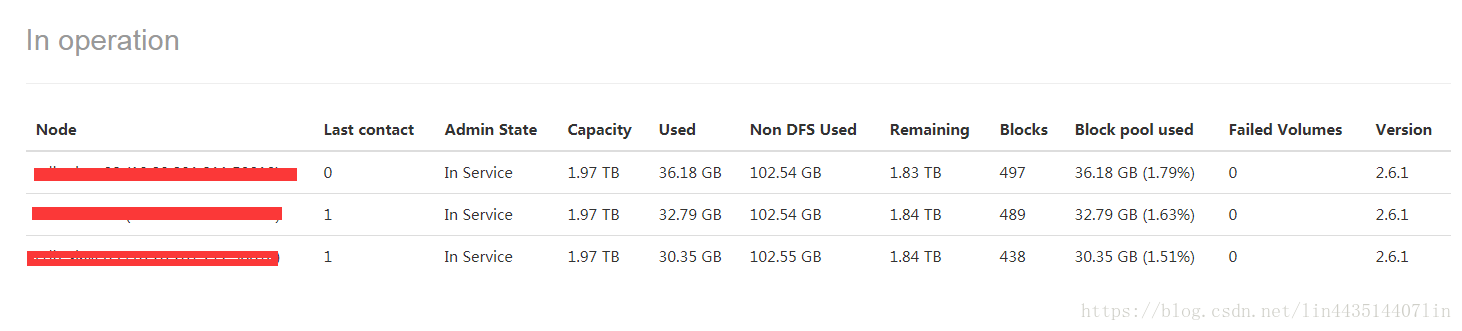
集群节点状态信息指标
2、取自hadoop的jmx指标
1、资源使用情况指标
http://**.**.***.208:50070/jmx?qry=Hadoop:service=NameNode,name=NameNodeInfo
http://**.**.***.209:50070/jmx?qry=Hadoop:service=NameNode,name=NameNodeInfo
2、负载情况
http://**.**.***.208:50070/jmx?qry=Hadoop:service=NameNode,name=FSNamesystem
http://**.**.***.209:50070/jmx?qry=Hadoop:service=NameNode,name=FSNamesystem
3、对于每个RPC服务监控指标
http:///**.**.***.208:50070/jmx?qry=Hadoop:service=NameNode,name=RpcActivityForPort8020
http:///**.**.***.209:50070/jmx?qry=Hadoop:service=NameNode,name=RpcActivityForPort8020
"RpcProcessingTimeAvgTime" : ,
"CallQueueLength" : 0
#Hadoop Configurations
#HdfsHead----url
HdfsHead_metrics_url01=http://**.**.***.208:8088/ws/v1/cluster/metrics
HdfsHead_metrics_url02=http://**.**.***.209:8088/ws/v1/cluster/metrics
#getLiveNodeInfo----url
hadoop_getNodeInfo_url01=http://**.**.***.208:50070/jmx?qry=Hadoop:service=NameNode,name=NameNodeInfo
hadoop_getNodeInfo_url02=http://**.**.***.209:50070/jmx?qry=Hadoop:service=NameNode,name=NameNodeInfo
#getload----url-----tag.HAState/tag.Hostname/TotalLoad
hadoop_getload_url01=http://**.**.***.208:50070/jmx?qry=Hadoop:service=NameNode,name=FSNamesystem
hadoop_getload_url02=http://**.**.***.209:50070/jmx?qry=Hadoop:service=NameNode,name=FSNamesystem
参考:
https://cwiki.apache.org/confluence/display/EAG/Hadoop+JMX+Monitoring+and+Alerting#HadoopJMXMonitoringandAlerting-MetricsCollector
https://hadoop.apache.org/docs/r2.8.4/hadoop-yarn/hadoop-yarn-site/ResourceManagerRest.html
http://hadoop.apache.org/docs/r2.5.2/hadoop-project-dist/hadoop-common/Metrics.html#rpc
http://hackershell.cn/?p=1355